
Feb 19, 2021
Learning, Evaluating and Optimizing Behavior Policies for Autonomous Vehicles
This blog-post provides a brief overview of my Ph.D. thesis. It deals with learning behavior policies for autonomous vehicles, evaluating these at run-time, and post-optimizing these to achieve safe and smooth driving behaviors. A novel graph neural network architecture for actor-critic reinforcement learning methods is introduced. Further, to boost the performance of learning, potential-based reward shaping for dynamic environments is introduced. A counterfactual behavior policy evaluation is proposed to evaluate the learned behavior policies at run-time. And finally, a post-optimization is introduced to obtain safe and comfortable behaviors using learned behavior policies.
Graph Neural Network Actor-Critic Architecture
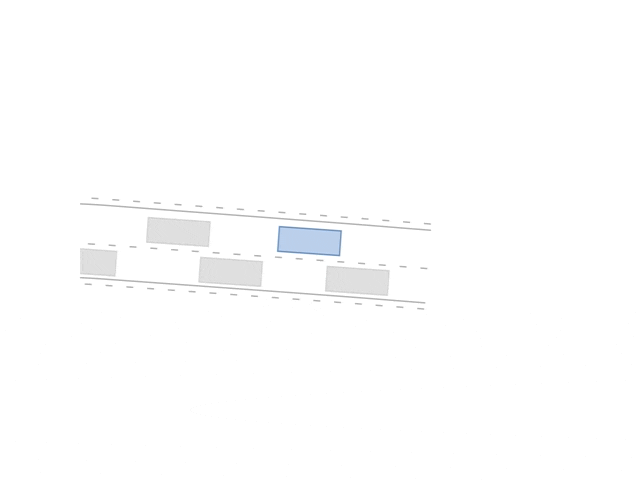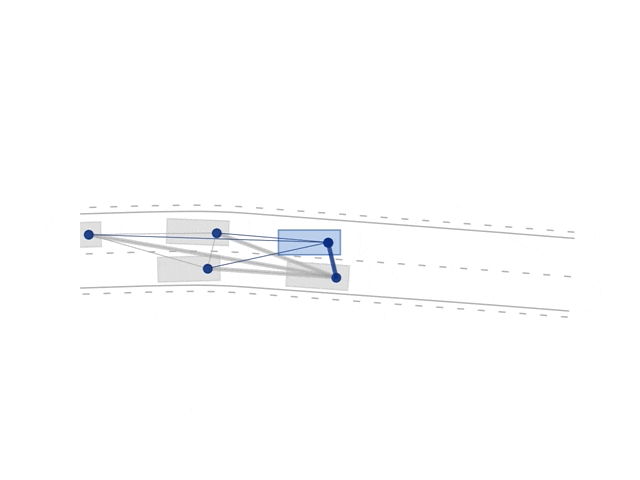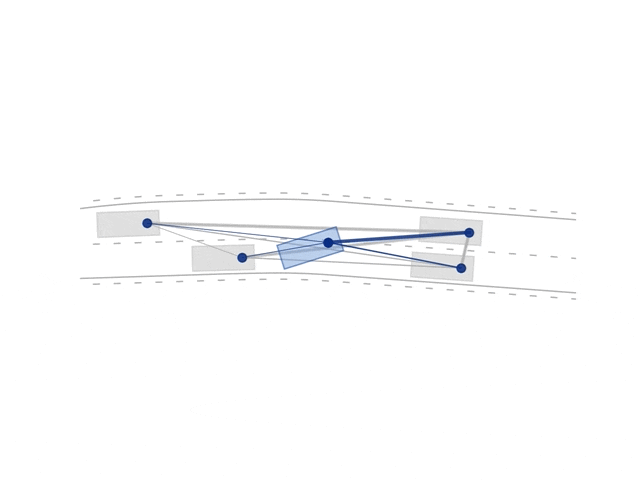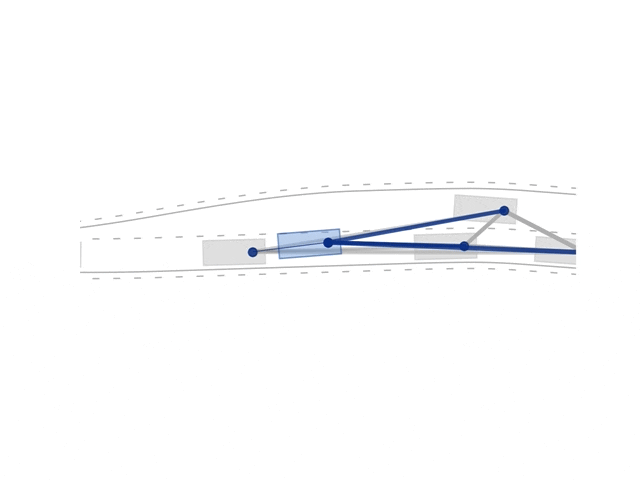
A novel graph neural networks (GNN) architecture for actor-critic reinforcement learning for learning behavior policies is proposed [1]. Allowing for learning directly on graph-structured data in which nodes are the vehicles and edges the relative value between these. Graphs and GNNs are invariant to the number and order of objects in the scene and inherently support a form of combinatorial generalization — making these ideal candidates for learning behaviors in dynamic environments. The GNN architecture is comprised of graph block layers and conventional dense layers that either output an action distribution or a scalar value depending on if used in the actor- or critic-network, respectively. The novel architecture is benchmarked against conventional networks, variational studies to evaluate generalization capabilities are performed, and insights into the GNN networks are visualized and quantified. The GNN architecture has been shown to outperform conventional deep neural networks (DNNs) and generalize better.
Reward Signal and Shaping

In complex and uncertain environments, the Markov decision process (MDP) can be utilized to formulate a sequential decision-making problem. A discounted MDP is defined by a tuple of states s, actions a, rewards r, transition probabilities p, and a discount factor γ:
By using model-free reinforcement learning, restricting the use-case to autonomous driving, and by pre-defining the states either to be in feature vector or graph form, only the reward signal r and the discount factor γ remains to be defined. The reward signal r is crucial for obtaining well-performing behavior policies, avoiding the credit assignment problem, and exploring the configuration space efficiently.
In this work, a potential-based reward shaping is introduced for dynamic environments, that guides the learning algorithm but leaves the optimal policy invariant. The reward shaping transforms the sparse reward signal (+1 for reaching the goal, -1 for having a collision, and 0 otherwise) into a continuous reward signal. Several reward shaping functions are proposed and benchmarked. It is shown that these can boost performance during learning significantly.
Evaluating Learned Behavior Policies

Small shifts in the distributions between training and application, noise, generalization capabilities can lead to unsafe driving behaviors using DNNs. Full-coverage off-line verification and validation are not possible due to the vast parameter- and behavior-space traffic scenarios span. For evaluating the performance at run-time, a counterfactual behavior policy evaluation (CBPE) is proposed in which non-factual behaviors are modeled [2]. Allowing to answer counterfactuals in the form of "Would my behavior policy have been safe if the other vehicle had changed lanes?". The proposed CBPE can, e.g., be used in run-time safety assurance systems, such as in a Simplex architecture's decision logic.
Post-Optimizing Learned Behavior Policies

Due to exploration limitations, using function approximators, and generalization capabilities, learned behavior policies tend to produce non-smooth behaviors — decreasing the comfort of the passengers. Contrary, optimization-based approaches offer optimal solutions for an optimal trajectory optimization problem formulation and, thus, safe and smooth behaviors. However, the computational complexity of global optimization increases in most approaches exponentially with the number of vehicles and local optimization requires good initial estimates to perform well. A local post-optimization is proposed that utilizes the learned behavior policy to obtain initial estimates and to derive state-constraints [3]. The post-optimized learned behavior trajectory is guaranteed to adhere to the constraints whilst minimizing the jerk — offering overall more comfortable trajectories than the learning-based behavior policies.
BARK and BARK-ML
During the course of the Ph.D. and time at fortiss, I co-founded the simulation framework BARK and initiated its machine learning extension BARK-ML [4]. These were created out of the need for developing and making behavior generation approaches benchmarkable with each other. All results and evaluations performed in the thesis have been obtained using these simulation frameworks.
Summary
In summary, the novel GNN actor-critic network architecture outperforms conventional DNNs, allows for additional insights, and generalizes better. The proposed potential-based reward shaping functions boost learning performance and lead to more efficient exploration. A counterfactual behavior policy evaluation offers insights into learned behavior policies at run-time and how these would cope with non-factual behaviors of others. And finally, the proposed post-optimization enables obtaining safe and smooth trajectories using learning-based behavior policies.
Thesis Relevant Publications
[1] Patrick Hart and Alois Knoll. Graph Neural Networks and Reinforcement Learning for Behavior Generation in Semantic Environments. 2020 IEEE Intelligent Vehicles Symposium (IV)
[2] Patrick Hart and Alois Knoll. Counterfactual Policy Evaluation for Decision-Making in Autonomous Driving. IROS 2020 Workshop Perception, Learning, and Control for Autonomous Agile Vehicles
[3] Patrick Hart, Leonard Rychly, and Alois Knoll. Lane-Merging Using Policy-based Reinforcement Learning and Post-Optimization. 2019 IEEE Intelligent Transportation Systems Conference (ITSC)
[4] Julian Bernhard et al. BARK: Open behavior benchmarking in multi-agent environments. IROS 2020